Hallo Herr Mergenthaler
Grüße Thomas Hermann
Ansatz 1
Ich habe zunächst eine sehr einfache Sonifikationsstrategie genommen:
- aus Wortnr/Minute habe ich eine Schätzung für den
Zeitstempel jedes Wortes generiert..
- n Minuten in denen viele Wörter gesprochen wurden sind
die Wörter gemäß dieser
Schätzung also zeitlich dichter.
Nun wird dieser Datensatz einfach sonifizert indem abhängig von
den binären Merkmalen ein
Klang erzeugt wird.
- Für positive/negative Emotion wird ein hoher/tiefer Sinuspuls
generiert.
(Frequenzverhältnis 1 Oktave)
- für hohe/niedrige ref. Act. wird ein helles/dunkles Clicken (Clave
Instrument) erzeugt.
Sound Beispiel: Claves
- Für abstrakte Worte wird ein helles 'ting' erzeugt.
Sound Beispiel: Cup Instr.,
ähnelt einem Ride-Becken im Schlagzeug)
Patient und Therapeut belegen dabei unterschiedliche Stereokanäle.
Bei mir erklingt der Patient links, der Therapeut rechts.
Hier die sonifikationen:
-
m2611a.wav
-
m2612a.wav
-
m2624a.wav
-
m2626a.wav
Zunächst aber interessiert mich, ob Sie die Dateien lesen/anhören
können. I
ich empfehle einen Hifi-Kopfhörer, z.B. Sony MDR-CD570 oder besser.
sollte der download zu lange dauern, speichern sie die Beispiele erst
lokal...
Hilfreich waere für mich ein zu den 4 Gesprächen aufbereiteter
Balken-plot,
wie Sie ihn mir gezeigt haben
Erste Erfahrungen:
1) der Höreindruck hängt stark von der zeitlichen Kompression
ab.
Um einzelne Wörter aufzulösen, sind Kompressionen
bis max 60 (d.h. 1min-> 1sec)
erforderlich. Bei noch größeren Kompressionen
löst sich die Einzelwortwahrnehmung
zu einer Verlaufsgestaltwahrnehmung auf.
2) die ref. act hat recht viele aufkommen - das macht die Sonifikation
sehr dicht.
3) Wortlängen in Länge der Marker ist nicht sehr sinnvoll,
da eine mindestlänge der Marker
für das Erkennen erforderlich ist. Marker zu großer
Länge aber wiederum andere Marker
akustisch verdecken können.
4) Die Alternative: Wortlänge = Lautstärke ist aber vielleicht
auch nicht sehr sinnvoll, da
hiermit lange Wörter den Sound dominieren (obwohl
sie vielleicht nicht wichtiger sind als
kurze Wörter.
Mein Eindruck ist, dass sich schon in dieser ersten Sonifikation Muster
in den Gesprächsverläufen
entdecken lassen. Insbesondere ragt das Gespräch m2612 heraus.
Hier pendelt die Aktivität von
Patient zu Therapeut...
Es fällt auf, dass besonders der Therapeut abstrakte Wörter
verwendet....
Ich halte als Strategie sinnvoll, gleitende Mittelwerte hinzuzunehmen.
Mein Vorschlag wäre z.B. alle N Wörter ein akustischer Marker
der
die Statistik innerhalb dieser Wörter (Mittelwert/Varianz) zusammenfasst.
Zudem könnte man kontinuierliche akustische Elemente einführen,
die z.B. nur zur Abweichung von Mittelwerten korrespondieren....
Ich bin gespannt auf Ihren ersten Eindruck
Thomas Hermann
Neue Ansätze (2001-09-09)
Hallo Herr Mergenthaler,
hier die Klangbeispiele zu den neuen Sonifikationsstrategien:
Ansatz 2
Dieser Ansatz benutzt sog. Auditory Buckets.
Je Attribut (emotional, abstrakt, CRA) wird ein Bucket eingerichtet.
Der Füllstand ist so gewählt, dass bei der gewählten Sitzung
der bucket Nb mal vollläuft, Bei jedem Überlauf eines buckets
wird der entsprechende bucket-Marker sound gespielt. Die Bucket-Marker
sind die gleichen wie oben, also Cup.wav für abstract, claves für
CRA und ein Ton für emotional.
Der Witz an diesem Ansatz ist nun, dass die Ausprägung (Lautstärke,
Frequenz) abhängig von statistischen Meßgrößen (z.B.
Abweichen vom Mittelwert) gesteuert wird.
Zur Wortdichte: diese habe ich jetzt per Kernel-Regression berechnet
mit gausschen Kernel mit Bandbreite 300 (wählbar). D.h. Wörter,
deren Wortindex weiter entfernt ist werden schwächer gewichtet. Die
so gewonnenen Wortdichtenkurven sehen so aus (noch nicht normiert):
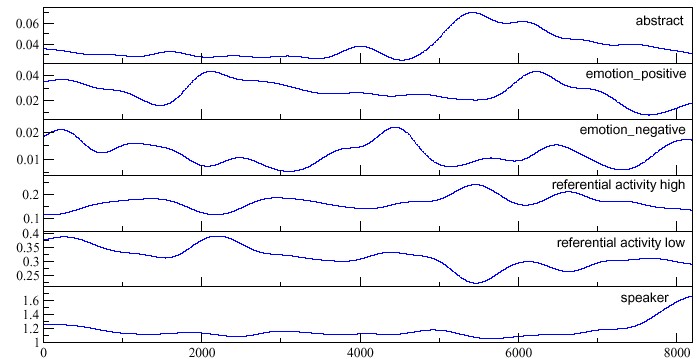
Folgendes Mapping wird nun für die Marker verwendet:
Frequenz: 2 Zustände, angewendet bei jeder Kategorie abstrakt,
emotional, CRA
-
hoch: wenn Wortdichte größer als der Mittelwert ist
-
tief: wenn Wortdichte unter Mittelwert liegt.
Amplitude: kontinuierlich:
-
Je stärker die Wortdichte vom Mittelwert abweicht, desto lauter der
Marker
Stereobalance: richtet sich wieder nach Sprecheranteil:
-
Signal rechts: nur der Therapeut redet
-
Signal links: nur der Patient redet
Hier die 4 Sitzungen, jeweils mit 10 Sek. Dauer für Sitzungen
26/12 bzw. 26/24
-
mb2612_10.wav
-
mb2624_10.wav
-
mb2612_5.wav
-
mb2624_5.wav
Ansatz 3
Dieser Ansatz ähnelt dem zweiten Ansatz sehr. Er wird nun ergänzt
durch sprachliche Marker. D.h. es wird eines der Wörter (connect,
reflect, relax und experience) gesprochen, wenn laut Tupel (Abstrakt/Emotion)
dieser Zustand vorliegt. Das Wort wird bei Erreichen des Thresholds gesprochen.
Es kann erst ein neues Wort gesprochen werden, wenn eine Refraktärzeit
vergangen ist. Dadurch wird gewährleistet, dass es kein Sprachwirrwarr
gibt... Die Lautstärke, mit der ein Wort gesprochen wird, korrespondiert
zur Qualität des Vektors.
Für die Analyse habe ich die Trajektorie im 2d-Raum (abstrakt-Wortdichte,
emotion-Wortdichte) dargestellt.
Hier ein Plot für Gespräch
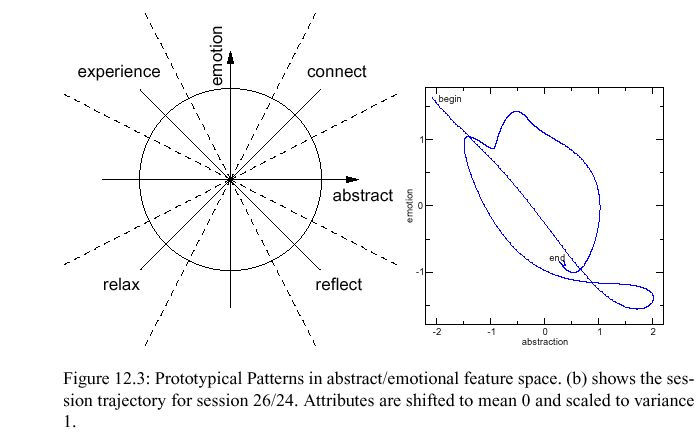
Das Wort wird also gesprochen, sobald die Trajektorie ins jeweilige
Segment hineingelangt.
Hier die Klangbeispiele:
-
mc2611_10.wav
-
mc2612_10.wav
-
mc2624_10.wav
-
mc2626_10.wav
Mein Kommentar:
ich finde, hiermit lassen sich schon besser die jeweiligen Zustände
des Patienten raushören.
Spannend wäre jetzt, für die Festlegung des Mittelwertes
eine größere Zahl von Sitzungen eines Patienten zu nehmen und
für die Sonifikation die Abweichungen der Wortdichte von diesen Mittelwerten
zu betrachten.
ich bin gespannt auf ihren Kommentar
Viele Grüße
Thomas Hermann