Universität Bielefeld - Technische Fakultät
6. Verbreitung von URTs
Da nun alle Informationen, die eine Ressource eindeutig beschreiben, in einem
URT zusammengefaßt sind, besteht nur noch das Problem, diesen allgemein
zugänglich zu machen. Verfahren wie archie oder Veronica, bei denen Server
in regelmäßigen Abständen nach neuen Ressourcen abgesucht
werden, haben einige Nachteile:
- Bei einer zu großen Zeitspanne zwischen zwei Bestandsaufnahmen
können Inkonsistenzen auftreten. Neue Ressourcen werden erst spät
erfaßt, gelöschte Ressourcen sind immer noch als vorhanden
aufgeführt.
- Eine Verkürzung der Zeitspanne würde die Netzauslastung stark
erhöhen: Zum einen können die zu übetragenden URTs recht
groß werden, zum anderen müssen, im Gegensatz zu archie oder
Veronica, eine Reihe weiterer Dienste berücksichtigt werden. Nimmt man
alle Dienste zusammen (ftp, gopher, WWW und andere), so ergibt sich eine
erheblich größere Datenflut, die übertragen werden muß.
- Falls sich nur wenige Informationen ändern, werden viele Daten
unnötig übertragen.
Das Ziel ist also ein Verfahren, daß möglichst viele Informationen
bei möglichst geringer Netzauslastung übertragen kann.
6.1 Resource Transponder
Die Idee ist eigentlich recht naheliegend: Information wird nur dann
übertragen, wenn es erforderlich ist. Das heißt, wenn sich
Informationen zu einer Ressource ändern, muß dies mitgeteilt werden.
Der Trick ist jetzt, daß die Ressource diese Aufgabe selbst
übernimmt. Dazu ist sie mit einem Sender, dem Resource Transponder
verbunden. Jedesmal, wenn sich der ihr zugehörige URT ändert, sendet
der Transponder ihn in das Netz. Der URT kann dann von geeigneten Rechner, in
denen diese Informationen gesammelt werden, aufgefangen und ausgewertet
werden.
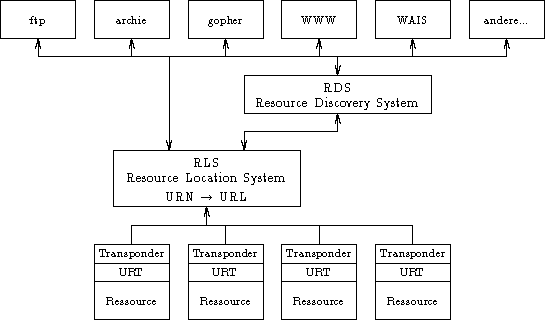
Die abgestrahlten URTs werden dann von einem oder mehreren Rechnern aufgefangen
und so aufgearbeitet, daß Benutzer in diesen Informationen gezielt nach
Ressourcen suchen können. Das gesamte Netzwerk würde dann die in
Abbildung 2 gezeigte Struktur erhalten. Informationen können nur auf den
gezeigten Verbindungen weitergegeben werden. Erst wenn eine gewünschte
Ressource gefunden wurde, nimmt die oberste Schicht direkt Verbindung mit der
Ressourcen-Ebene auf.
Abildung 2: Schema der Weitergabe von Ressource-Informationen
6.1.1 Die Ressourcen-Ebene
Auf der untersten, der ersten Ebene befinden sich die eigentlichen Ressourcen.
Untrennbar mit jeder einzelnen Ressource verbunden ist ihr URT, der alle
wichtigen Informationen enthält, die öffentlich bekannt gemacht
werden sollen. Außerdem ist ein Transponder direkt mit der Ressource
verknüpft, der immer dann sendet, wenn die Ressource verändert wird.
Dies kann mehrere Gründe haben:
- die Ressource wird erschaffen
- die Ressource wird an einen anderen Ort verlegt
- eine Kopie der Ressource wird an einem anderen Ort angelegt
- der URC der Ressource wird verändert
- die Ressource wird gelöscht
Unter Umständen könnte es sich als sinnvoll erweisen, einen
Transponder von außen zum Senden anregen zu können. Falls ein
Rechner der zweiten Ebene sicher ist, eine inkonsistente Datenbank zu haben,
könnte er gezielt seine Informationen auffrischen, und müßte
nicht erst auf den nächsten Sendevorgang der Ressource warten.
In einer Weiterentwicklung des gesamten Konzeptes wird der Transponder durch
einen Agenten ersetzt, der weiterhin Informationen aussendet. Aber dieser Agent
hat auch die Aufgabe, Zugriffe auf die Ressource zu koordinieren, d.h.
insbesondere nur solchen Personen Zugriff zu gewähren, die dazu eine
Erlaubnis haben. Auf diese Weise könnte die Sicherheit von Ressourcen im
Netz stark erhöht werden.
6.1.2 Das Resource Location System
Auf der zweiten Ebene befindet sich das Resource Location System (RLS). Seine
Aufgabe besteht darin, gegebene URNs in zugehörige URLs umzuwandeln. Dazu
wertet es die ankommenden URTs der Ressourcen aus und legt die URNs und URLs im
wesentlichen in einer großen Tabelle ab. Die anderen Informationen, die
in den URCs enthalten sind, werden an die dritte Ebene weitergereicht.
Wenn nun ein Benutzer Zugriff auf eine Ressource haben möchte, zu der er
nur den URN hat, kann er hier einen oder mehrere URLs ermitteln. Er erhält
aber keine weiteren Informationen über die Ressource. Dies erledigt die nächste
Ebene.
6.1.3 Das Resource Discovery System
Auf der dritten Ebene befindet sich das Resource Discovery System (RDS). Es
stellt vermutlich den mächtigsten Teil des ganzen Systems dar. Seine
Aufgabe besteht darin, die URCs der Ressourcen zu archivieren. Wenn ein
Benutzer ein Programm sucht, zu dem er einen URN hat, kann er hier genauere
Informationen erhalten. Insbesondere kann er sich die URCs ansehen.
Der eigentliche Sinn des RDS besteht darin, daß es möglich sein
soll, Querverweise zu verwandten Ressourcen zu finden. Auf diese Weise
wären umfangreiche Recherchen im Netz möglich. Der Benutzer
bräuchte nur noch einen Suchbegriff angeben, worauf er eine Reihe von URNs
erhält, die Informationen zu diesem Begriff enthalten. Somit könnte
man nicht nur nach allen ftp-baren Dateien zu einem Thema suchen, sondern man
würde automatisch alle gopher-Server, WWW-Hypertextseiten und
WAIS-Datenbanken zu einem bestimmten Thema erhalten.
Teilweise ist die Funktionalität der Ebenen zwei und drei die selbe,
nämlich zu einem URN passende URLs bzw. URCs zu liefern. Daher liegt es
nahe, die beiden Dienste zusammenzufassen. Ein Grund, dies im Augenblick nicht
zu tun, ist die technische Machbarkeit der dritten Ebene. Die zweite Ebene kann
relativ leicht durch das X.500-Protokoll realisiert werden, dies würde
aber nicht die Funktionalität der dritten Ebene liefern. Daher wird
vermutlich erst einmal das RLS realisiert werden, und das RDS wird dann
später eingerichtet.
6.1.4 Die Client-Programme
Auf der obersten Ebene befinden sich die derzeit bekannten Systeme, die einen
Zugang zu den verschiedenen Netzdiensten ermöglichen. Vermutlich werden
neue Dienste dazukommen, um alle Möglichkeiten wirklich ausschöpfen
zu können.
Falls lediglich ein bekannter URN in einen URL umgewandelt werden muß,
können die bestehenden Programme relativ einfach darauf umgestellt werden.
Insbesondere WWW-Clients wie Mosaic bieten sich hier an, da sie bereits jetzt
eine Reihe von Protokollen darstellen können. Der Zugriff auf das RLS
könnte für den Benutzer völlig unsichtbar verlaufen, falls nur
ein Ort für eine Ressource gefunden wurde. Sonst könnte erst eine
WWW-Seite mit Links zu allen gefunden Ressourcen gezeigt werden, von der der
Benutzer dann die gewünschte auswählt. Die Funktionsweise von Mosaic
würde sich dabei aus der Sicht des Benutzers nicht wesentlich
ändern.
6.2 Eine mögliche Realisierung
Wenn sich die Systeme RLS und RDS prinzipiell realisieren lassen, stellt sich
immer noch die Frage, wie sie dann aufgebaut sein sollen. Als mögliche
Betreiber dieser Systeme würden sich natürlich die Verlage anbieten,
die die Ressourcen zur Verfügung stellen.
Interessant ist auch, ob es ein universelles System geben soll, das
alle Ressourcen verwaltet, oder ob es mehrere getrennte Systeme geben
soll. Es wurde vorgeschlagen, Resource Discovery Systeme für spezielle
Themengebieten einzurichten. Ein oberstes System könnte dann eine Anfrage
an ein geeignetes RDS weiterreichen. Auf diese Weise würde ein RDS-Server
selbst zu einer Ressource werden. Das Verfahren ist dann ähnlich wie unter
WAIS, wo die oberste Datenbank spezialisierte WAIS-Server kennt, an die der
Benutzer weitervermittelt wird.
Weiter mit dem Glossar, zurück zu
Kapitel 5 oder ganz zurück zum
Inhaltsverzeichnis.
Jörn Clausen, 1994-10-06